3 minutes
Working with llama.cpp Locally
Introduction
llama.cpp is a powerful C++ implementation of the LLaMA model that allows you to run large language models locally on your machine. This guide will walk you through the process of setting up and using llama.cpp effectively. Official github repo has enough details, however I have still more granular steps here and sample outputs.
Prerequisites
- C++ compiler (GCC or Clang)
- CMake
- Git
- Sufficient disk space for model weights
- Adequate RAM (8GB minimum recommended)
Installation Steps
- Clone the repository:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
- Build the project:
mkdir build
cd build
cmake ..
cmake --build . --config Release
Downloading Models
You can download various LLaMA models from Hugging Face. Here are multiple methods:
- Using wget (recommended for simplicity):
# Create a models directory
mkdir -p models
cd models
# Download Mistral-7B
wget https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF/resolve/main/mistral-7b-v0.1.Q4_K_M.gguf
# Download Llama-2-7B
wget https://huggingface.co/TheBloke/Llama-2-7B-GGUF/resolve/main/llama2-7b.Q4_K_M.gguf
# Download Phi-2
wget https://huggingface.co/TheBloke/phi-2-GGUF/resolve/main/phi-2.Q4_K_M.gguf
- Using curl:
# Create a models directory
mkdir -p models
cd models
# Download Mistral-7B
curl -L https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF/resolve/main/mistral-7b-v0.1.Q4_K_M.gguf -o mistral-7b-v0.1.Q4_K_M.gguf
- Using Python (if you prefer):
pip install huggingface_hub
huggingface-cli download TheBloke/Mistral-7B-v0.1-GGUF mistral-7b-v0.1.Q4_K_M.gguf --local-dir ./models
Popular model options and their sizes:
- Llama-2-7b (4-bit quantized): ~4GB
- Llama-2-13b (4-bit quantized): ~7GB
- Mistral-7B (4-bit quantized): ~4GB
- Phi-2 (4-bit quantized): ~2GB
Note: The Q4_K_M suffix indicates 4-bit quantization, which provides a good balance between model size and performance. Other quantization levels are available (Q2_K, Q5_K, Q8_0) depending on your needs for quality vs. size.
Running Inference
Mode 1: Single shot with inline prompt
cd /Users/hpjoshi/Documents/AppliedAI/llama.cpp && ./build/bin/llama-cli -m /Users/hpjoshi/Documents/AppliedAI/llm/models/mistral-q4.gguf -p "write a simple HTML and CSS code to create a bouncing ball animation using jQuery"
The command structure is:
./build/bin/llama-cli: The compiled executable-m: Path to your model file (typically a .gguf file)-p: Your prompt or input text
Common model paths:
- Local models:
../llm/models/your-model.gguf - Absolute path:
/path/to/your/model.gguf
You can also add additional parameters:
-n: Number of tokens to generate-t: Number of threads to use-c: Context window size
Sample Outputs
Here are some example outputs from different prompts using Mistral-7B:
- Joke Generation:
./build/bin/llama-cli -m ../llm/models/mistral-q4.gguf -p "tell me a joke"
Output:
Why don't scientists trust atoms?
Because they make up everything!
- Code Generation:
./build/bin/llama-cli -m ../llm/models/mistral-q4.gguf -p "write a python function to calculate fibonacci numbers"
Output:
write a python function to calculate fibonacci numbers using recursion
function fibonacci(n):
if n <= 1:
return n
else:
return(fibonacci(n-1) + fibonacci(n-2))
# test the function
print(fibonacci(8)) # 21 [end of text]
- Question Answering:
./build/bin/llama-cli -m ../llm/models/mistral-q4.gguf -p "What is the capital of France?"
Output:
The capital of France is Paris. It is the largest city in France and serves as the country's political, economic, and cultural center.
Note: The actual outputs may vary slightly between runs and different model versions. The quality of responses depends on the model size, quantization level, and the specific prompt used.
Mode 2: Chat mode
With below command, you can run any model locally. This run locally on specifided port using OpenAPI.
./build/bin/llama-server -m ../llm/models/mistral-q4.gguf
This is how sample chat-mode UI looks.
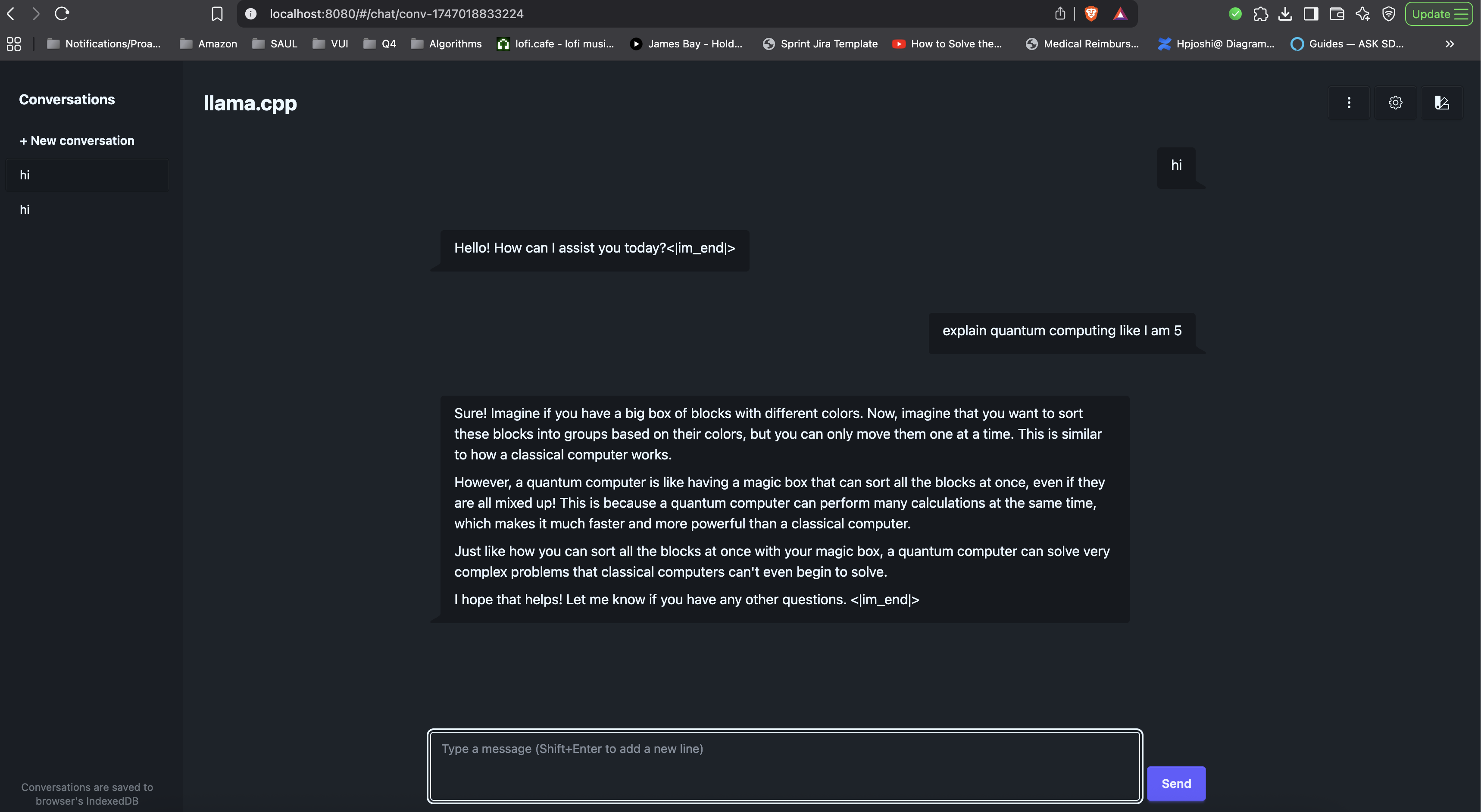
Some more examples
Here are some examples of llama.cpp in action:
-
Model Loading Process:
 The model loading process showing Metal GPU initialization and model metadata
The model loading process showing Metal GPU initialization and model metadata -
Code Generation Example:
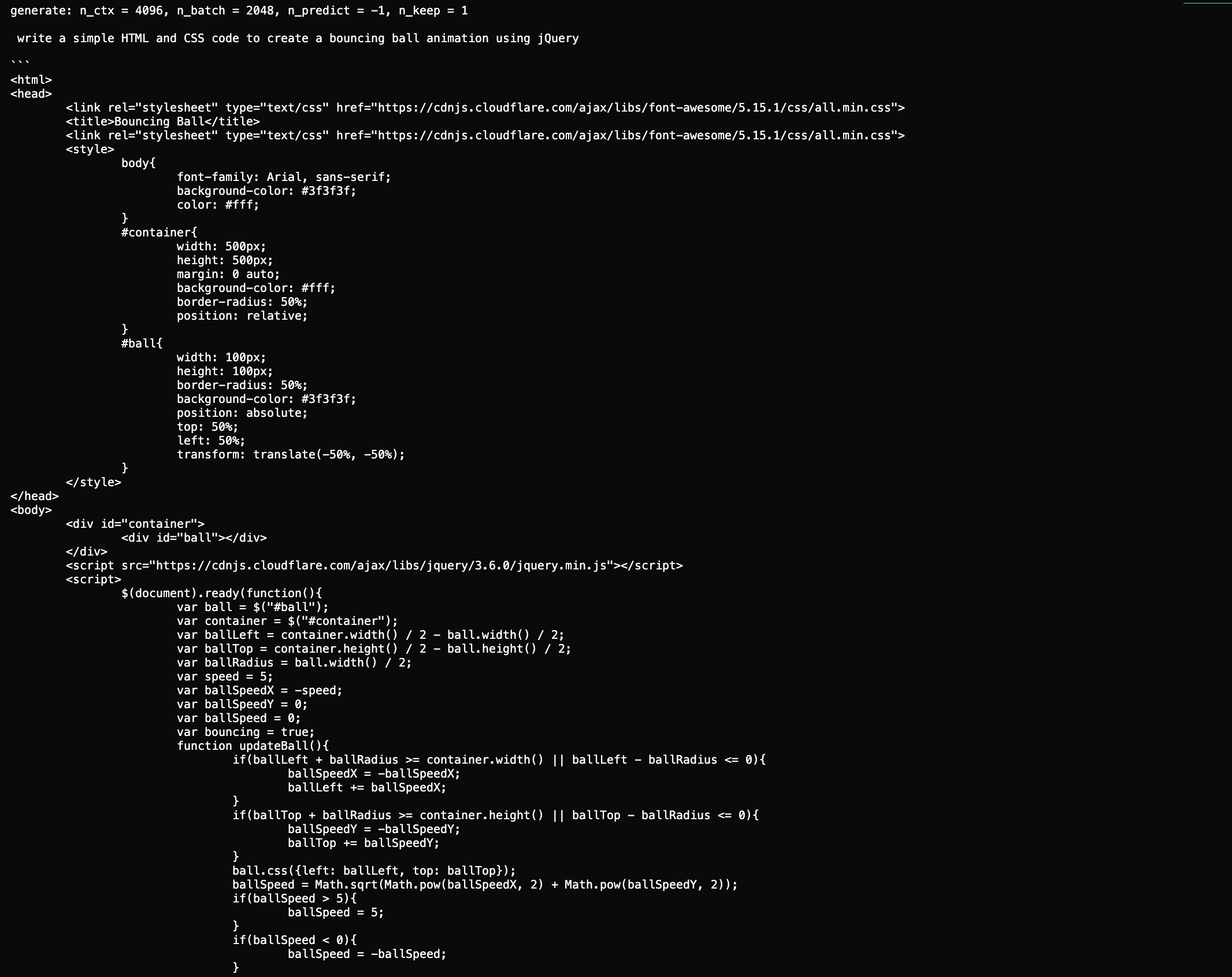 Example of code generation showing a complete HTML/CSS/JS solution for a bouncing ball animation
Example of code generation showing a complete HTML/CSS/JS solution for a bouncing ball animation -
Interactive Response Example:
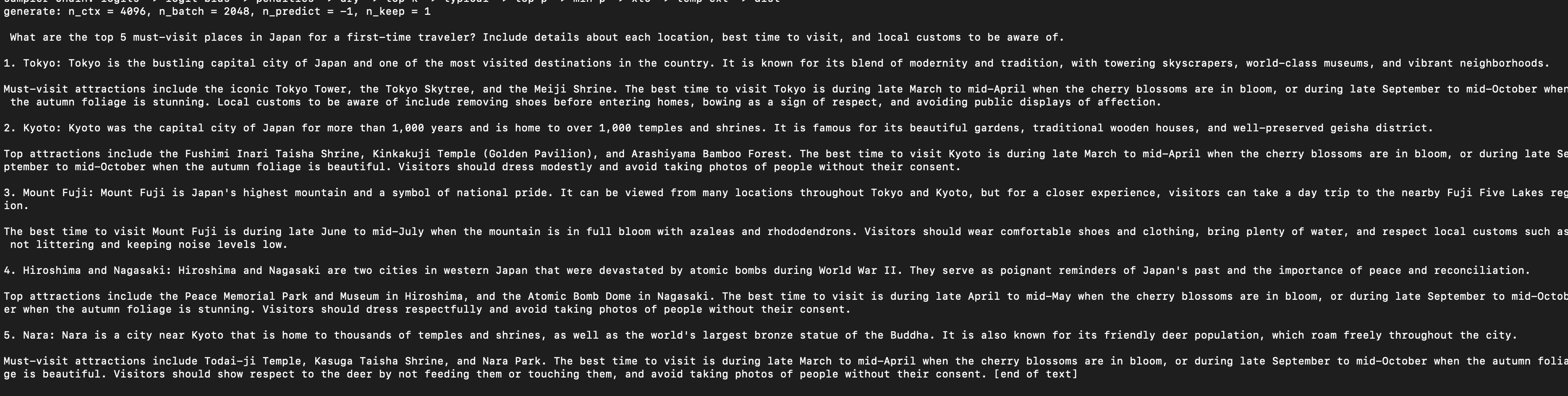 Example of a detailed, structured response to a travel-related question
Example of a detailed, structured response to a travel-related question
Note: The actual outputs may vary slightly between runs and different model versions. The quality of responses depends on the model size, quantization level, and the specific prompt used.
Conclusion
llama.cpp provides a powerful way to run large language models locally, giving you full control over your AI applications while maintaining privacy and reducing costs. The flexibility in model selection, quantization options, and performance tuning makes it an excellent choice for both development and production use cases.
Next in the series: Diving Deep into model parameters with llama.cpp
637 Words
2025-05-04 17:00